
MCP : le protocole qui ouvre la voie à l’IA agentique en entreprise
28 juillet 2025
Le protocole MCP standardise la communication entre agents IA et systèmes, ouvrant la voie à une IA agentique scalable en entreprise.
Data science
Innovation
Après « NFT » en 2020/21, « métavers » en 2021/22, « ChatGPT » pourrait sans aucun doute être considéré comme le « buzzword de l’année 2022/23 ». Acclamé ou déclamé, il est fortement débattu sur les plateaux de télévision, les réseaux sociaux, et au sein des entreprises. Est-ce l’émergence d’une technologie révolutionnaire, au même titre que l’apparition des micro-processeurs, comme le pointe Bill Gates, ou simplement « la popularisation d’une technologie déjà existante » comme l’évoque Yann LeCun, directeur scientifique IA de Facebook ?
La réponse se situe probablement entre les deux. Oui, ChatGPT apporte de nombreuses avancées en termes de traitement du langage humain. Utilisé adroitement, il permet d’améliorer nettement les performances de certains modèles d’IA, auparavant à la pointe de la technologie. Mais derrière ChatGPT se cachent des modèles de langage connus depuis plusieurs années, déjà largement utilisés et exploités par les experts en IA, notamment chez eleven, avec l’accompagnement de plus d’une dizaine de projets types pour des acteurs industriels et des start-ups.
ChatGPT, le chatbot développé par OpenAI, est l’une des applications d’une technologie en plein essor depuis 2018 : les LLMs, ou Modèles d’Apprentissage de Langue. Parfois également appelés « modèles de fondation », ils sont le cœur de la compréhension du langage humain par la machine. Pour ce faire, ils se basent sur une architecture complexe de réseaux de neurones, et des centaines de milliards de paramètres à ajuster par itération. Le principe est simple : pour un échantillon de phrase donné, prédire le mot suivant.
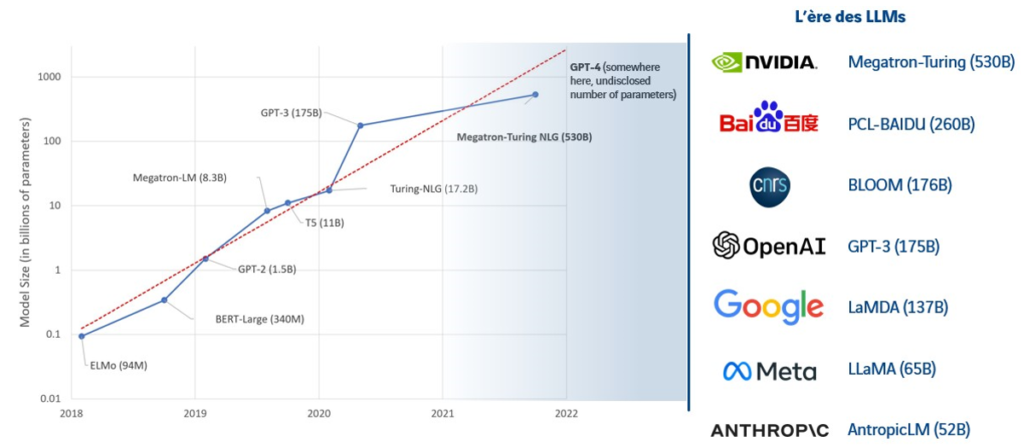
L’IA détermine ainsi la signification d’un mot en prenant en compte les contextes dans lesquels elle l’a croisé. L’entrainement d’un modèle avec autant de paramètres nécessite une grande quantité de données, issues généralement de données publiquement accessibles telles que Wikipedia (3% du corpus d’entainement), des articles de presses, des livres en libre accès, etc. A titre d’exemple, GPT-3 (Generative Pre-trained Transformers-3), composé de 175 milliards de paramètres, a nécessité l’ingestion de près de 570 Go de données, soit environ 300 milliards de mots. Ces chiffres pharaoniques sont synonymes de coûts financiers considérables : on parle de 4,6 millions de dollars dépensés pour l’entrainement de GPT-3, sans compter l’impact écologique en découlant.
Figure 1 : Evolution du nombre de paramètres utilisés par les modèles LLMs depuis 2018 (4)

Il en résulte des modèles d’IA très puissants, capables de comprendre toute la sémantique de chaque langue sur laquelle ils ont été entrainés, ce qui leur permet de réaliser de nombreux cas d’usage : traduction de textes, rédaction d’essais, etc… Plus largement, ils peuvent être spécialisés, c’est-à-dire adaptés à un cas d’usage, leur conférant un large éventail de tâches possibles, comme ChatGPT.
ChatGPT est un chatbot basé sur GPT-3 capable d’émuler l’expérience humaine d’une conversation réelle. Treize mille couples de questions/réponses ont été utilisés pour transformer un modèle de « prédiction du mot suivant » en un modèle capable de répondre à des questions. En parallèle, un modèle de récompense – d’apprentissage par renforcement – aide ChatGPT à s’orienter vers la production de réponses attendues par un humain. Cette dernière étape, lors de laquelle des humains classent différentes réponses possibles pour une même question, permet la modération de certains contenus considérés comme illégaux ou dangereux.
Malgré ses performances remarquables, ChatGPT souffre à ce jour de sévères limites éthiques et techniques.
D’un point de vue éthique, la technologie se confronte à plusieurs problématiques de taille, liées à son fonctionnement et à son processus d’entrainement.
Les LLMs basés sur l’open data et disponibles en open source tels qu’Alpaca, développé par Stanford, répondent aux limites de confidentialité et de propriété intellectuelle, mais performent moins bien et restent sensibles aux biais et contenus nuisibles.
ChatGPT fournit une réponse plausible, qui dénote le moins, au vu de tous les contextes qu’il a rencontré lors de son entrainement. Il ne connait donc pas le concept de vérité. De ce point clé découlent plusieurs limites techniques :
Plusieurs options existent pour contourner ces limites techniques : le recours à des frameworks permettant de sourcer les informations et de chercher sur des sources externes (comme LangChain), l’utilisation de GPT-4 (la dernière version payante d’OpenAI et plus performante), ou la spécialisation de ChatGPT à des cas d’usage spécifiques.
Heureusement, il ne s’agit tout d’abord pas d’entrainer un modèle de language from scratch, mais de bénéficier de son apprentissage de la langue pour lui faire effectuer des tâches précises. On parle de « Transfert Learning » lorsqu’on ajuste un modèle pré-entrainé sur un cas d’usage spécifique, étape significativement moins énergivore.
ChatGPT est une technologie utile et prometteuse, qui, à l’avenir, pourrait être utilisée dans de nombreux domaines. Chez eleven, nous faisons face à un engouement des différents métiers à la hauteur de la médiatisation du sujet, et évoquons avec celles-ci de nombreuses applications :
Plus généralement, les modèles de langage peuvent être mis à contribution pour de nombreuses tâches, de l’automatisation des processus, aux tâches humaines complexes, telles que l’analyse des données et le traitement des documents.
Les projets qu’eleven a accompagné ont toutefois mis en lumière certains pré-requis pour une utilisation efficace de la technologie :
Suivant ces lignes de conduite, nous avons amélioré des performances d’extraction d’informations clés de PLU de 13% avec une méthode Plug & Play, à 55% avec une bonne pré-sélection du corpus et du « prompt engineering ». A noter que la meilleure performance obtenue sans les modèles de langage est de 26% pour un tel sujet, soit deux fois meilleur que GPT sans ajustements, et deux fois moins bien que GPT avec de l’accompagnement.
Eleven accompagne les entreprises dans l’expérimentation, le développement et l’intégration de ces outils pour des cas d’usage concrets. Avec une approche stratégique, des attentes réaliste, et surtout une compréhension claire de son fonctionnement et de ses limites, les entreprises peuvent véritablement bénéficier de la technologie derrière ChatGPT.
(1) https://www.independent.co.uk/tech/harvard-chatbot-teacher-computer-science-b2363114.html
(2) https://fr.wikipedia.org/wiki/GPT-3
(3) https://arxiv.org/pdf/2302.04023.pdf
(4) https://huggingface.co/blog/large-language-models
Partager
Sur le même sujet
28 juillet 2025
Le protocole MCP standardise la communication entre agents IA et systèmes, ouvrant la voie à une IA agentique scalable en entreprise.

25 juillet 2025
Le Legal Ops, levier de performance des directions juridiques, s'accélère grâce à l'IA générative, l'automatisation et la valorisation des données.