Maîtriser la construction d’un RAG (Retrieval Augmented Generation)11 octobre 2024
Data science
Generative AI
Innovation
L’essor de l’IA Générative (IA) et notamment des modèles de langage (LLM) révolutionnent les processus d’entreprise en offrant un levier de productivité des employés. Les techniques de Retrieval Augmented Generation (RAG), qui permettent d’intégrer une base de connaissance externe à un LLM, se distinguent comme une innovation majeure dans ce domaine. Ces techniques peuvent ainsi prévenir des hallucinations, problème majeur dans l’intégration des LLM dans les applications business.
Les applications business des RAG sont vastes et prometteuses. En tant qu’outil d’aide au service client, un RAG peut offrir des réponses précises et contextualisées, améliorant ainsi la satisfaction et la fidélité des clients ; dans le domaine de l’analyse de marché, il peut synthétiser des données complexes et fournir des insights précieux pour orienter les décisions stratégiques ; dans la vente, un assistant qui synthétise de nombreuses informations en temps réel, boostant ainsi les performances commerciales.
Cependant, la création d’un RAG performant n’est pas une tâche aisée. Elle nécessite une approche méticuleuse et une compréhension approfondie des besoins spécifiques de l’entreprise. Un développement mal conçu peut aboutir à un chatbot inefficace et décevant. Mais avec une stratégie bien pensée et une mise en œuvre rigoureuse, les RAG peuvent transformer les processus internes et devenir un véritable atout stratégique.
Qu’est-ce-qu’un RAG ?
Un RAG est une application des LLM (Large Language Models, type ChatGPT) qui combine deux techniques : la récupération d’information (retrieval) et la génération de texte (generation). En termes simples, un RAG est un ChatBot conçu pour rechercher des informations pertinentes dans une vaste base de données documentaire et les utiliser pour générer des réponses ou des contenus de manière cohérente et contextuelle. Cette technologie est particulièrement utile pour les entreprises qui doivent traiter de grandes quantités de données et fournir des réponses précises et rapides.
Les RAGs présentent de nombreux avantages, par exemple leur capacité à citer des informations lorsqu’ils répondent à la question, ou leur capacité à intégrer des informations en dehors de leur champ d’entraînement (données d’actualité, données internes à une entreprise…). Ils permettent de palier les faiblesses des LLM à savoir leur non-interprétabilité et l’absence de mise à jour de leur connaissance.
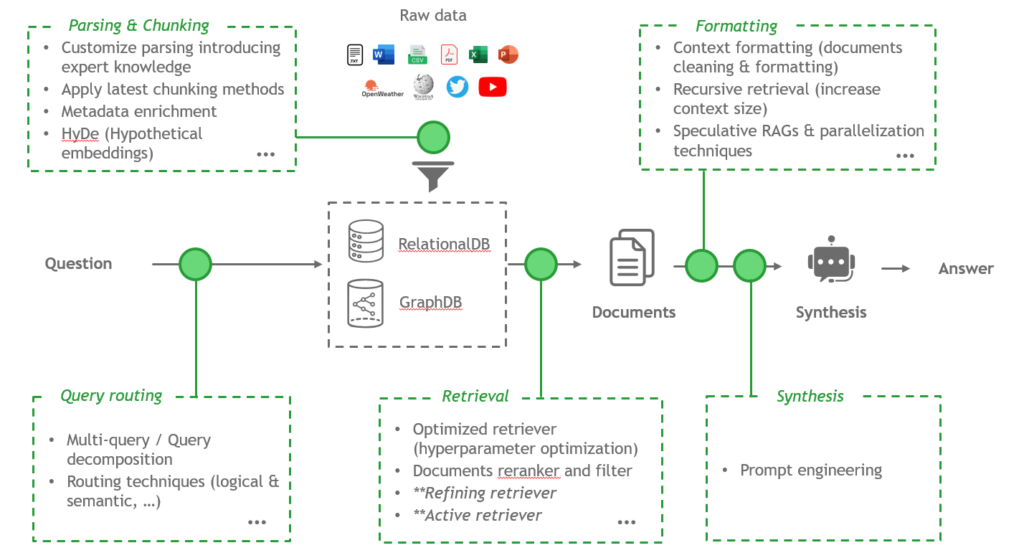
Pour comprendre comment fonctionne un RAG, il est utile de décomposer le processus en trois grandes briques principales : le parser, le retriever et la synthèse.
Le Parser : Il s’agit d’un composant qui extrait l’information depuis une base de données structurée (des tableaux), mais aussi de la donnée non structurée (des slides, des PDFs…). Cette brique élémentaire permettra d’extraire, puis structurer l’information qui sera ensuite fournie au chatbot.
Le Retriever : Ce composant permet la recherche d’informations pertinentes dans une base de données ou un ensemble de documents. Il permet d’identifier des bouts de textes (chunks), ou des documents qui permettraient de répondre à la question de l’utilisateur.
La Synthèse : Le dernier composant est le bloc de génération, ou de synthèse. Une fois que les documents pertinents ont été récupérés, un modèle de langage génère une réponse cohérente et contextuelle basée sur la base de données qui lui a été fournie.
Aucun de ces éléments ne doit être délaissé, au risque de diminuer considérablement les performances du RAG.
Optimiser un RAG
Afin optimiser un RAG, on peut améliorer chacune de ces briques individuellement, qui présente chacune de nombreux paramètres et challenges à part entière.
Le Parser : La difficulté principale du parser réside dans l’interprétation de documents complexe (des PDFs avec de l’interprétation graphique, visuelle…), mais il est possible de faire appels à des modèles d’OCR (Optical Character Recognition), ou encore à des modèles de langages (GPT Vision). Il y a en revanche un trade-off à choisir entre coûts, performance et hallucination (car les modèles de langages peuvent halluciner). Une autre brique importante du parser est l’enrichissement de la donnée avec de la « métadonnée ». On peut par exemple ajouter du contexte, du formatting, de la connaissance métier, afin d’enrichir le texte des documents.
Le Retriever : L’optimisation d’un retriever est un jeu d’équilibriste : il est nécessaire de trouver un optimum entre le nombre et la taille des documents retrouvés pour donner suffisamment d’information au LLM pour qu’il puisse répondre à la question, mais qu’il ne soit pas noyé dans les informations si on lui en donne trop. Par exemple, des méthodes avancées telles que les active/refining retrievers, ou les dynamic hyperparameters retrievers permettent d’ajuster les paramètres du modèle en fonction de la question de l’utilisateur (entre autres), et ainsi trouver le bon équilibre à chaque question.
La Synthèse : Enfin, la synthèse est probablement l’un des aspects les plus compliqués à traiter. Le succès d’une bonne synthèse réside dans le « prompt engineering », ou en d’autres termes, dans le message que l’on va envoyer au LLM (ou prompt). Le prompt doit respecter de nombreuses règles de format pour exploiter tout le potentiel des modèles de langage avancés. Il est par exemple possible d’implémenter des raisonnements aux LLMs avec des techniques de prompt avancées, via des raisonnements étape par étape comme le Chain of Thought (CoT) ou le Thread of Thought (ToT). De nombreuses techniques existent dans la littérature, et il est nécessaire d’avoir une méthode d’évaluation fiable pour tester plusieurs prompts rapidement.
Les clés de la réussite d’un RAG
La réussite d’un RAG passe par une architecture intelligente et une expertise de l’IA générative. Il est nécessaire de se concentrer sur certains points, par exemple :
Solution unique et personnalisée : Il n’existe aucune architecture de RAG valable pour tous les cas d’usages. Plus étonnant encore, on constate que toutes les techniques avancées mentionnées ci-dessus peuvent avoir des performances excellentes dans certains contextes, ma dégrader fortement la performance dans d’autres. Il est nécessaire d’être exhaustif lors des tests des différentes architectures, afin de maximiser ses chances d’avoir un outil performant
Architecture scalable : De nombreuses briques technologiques existent, mais ne se valent pas en termes de performance, coût et scalabilité. L’architecture doit être personnalisée au cas d’usage pour correspondre le mieux aux besoins métiers.
Un accompagnement de l’utilisateur : Si la performance de l’outil créé est importante, l’engagement des utilisateurs dans le projet l’est encore plus. L’utilisateur final doit co-construire l’outil en apportant sa vision au projet.
La prise en main de ces outils peut être déroutante et nécessite une période d’adaptation et de formation afin d’assurer une adoption maximale.
Conclusion
Si la construction d’un RAG peut apporter une valeur immense à de nombreux domaines au sein d’une entreprise, elle nécessite néanmoins une expertise approfondie pour éviter les pièges courants et garantir des performances et une adoption optimales. Eleven s’appuie sur un savoir-faire et une expérience approfondie de ces technologies pour accompagner ses clients de bout en bout dans leur transformation s’appuyant sur l’IA générative et les aider à tirer le meilleur parti de leur RAG.Pour en savoir plus sur la manière dont nous pouvons vous aider à intégrer un RAG dans votre entreprise, n’hésitez pas à nous contacter.
Pour en savoir plus, contactez Simon Georges-Kot expert en RAG – Principal – eleven strategy
L’intelligence artificielle au service de la tarification en contexte douanier incertain
23 mai 2025
Dans un contexte économique mondial de plus en plus instable, les variations des droits de douane constituent un enjeu stratégique majeur pour les entreprises. Anticiper…
L’IA au service de la réduction des coûts : de l’automatisation à la transformation agentique
15 avril 2025
L’Agentic Business Redesign (ABR) permet aux entreprises de repenser leurs processus autour des capacités des agents d’IA, pour gagner en efficacité et en agilité. Il…